
基于Storm Hbase 流式计算与存储的TPS6000调优
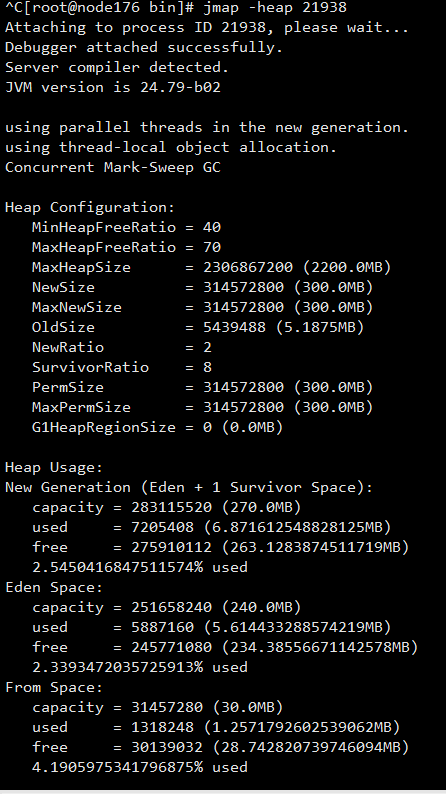
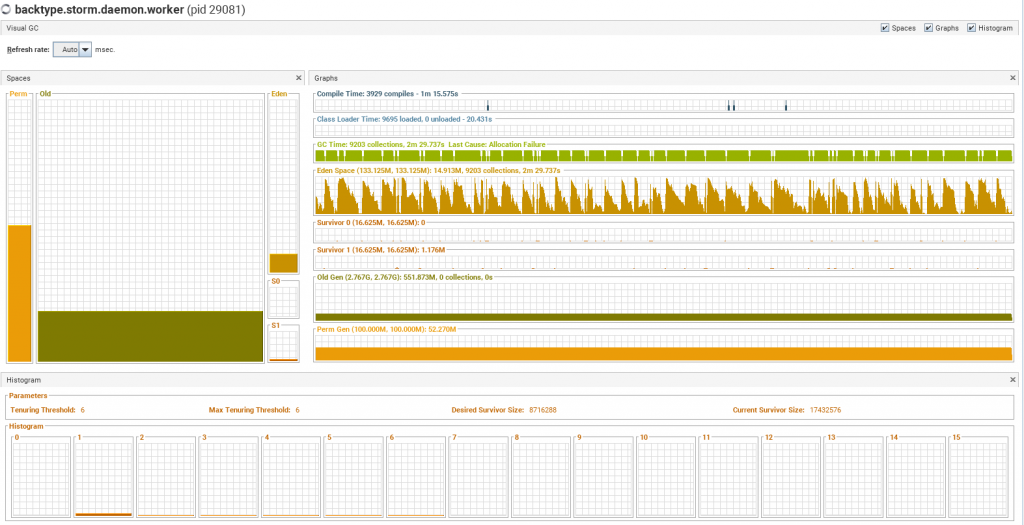
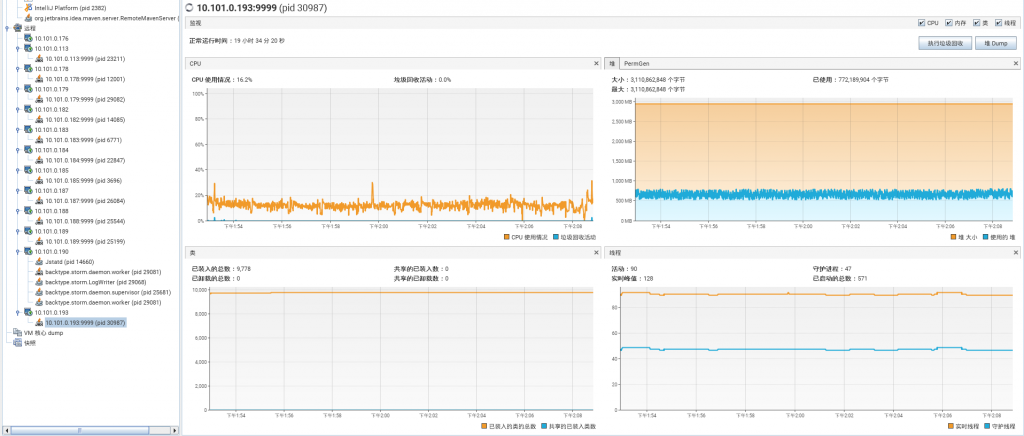
GC情况
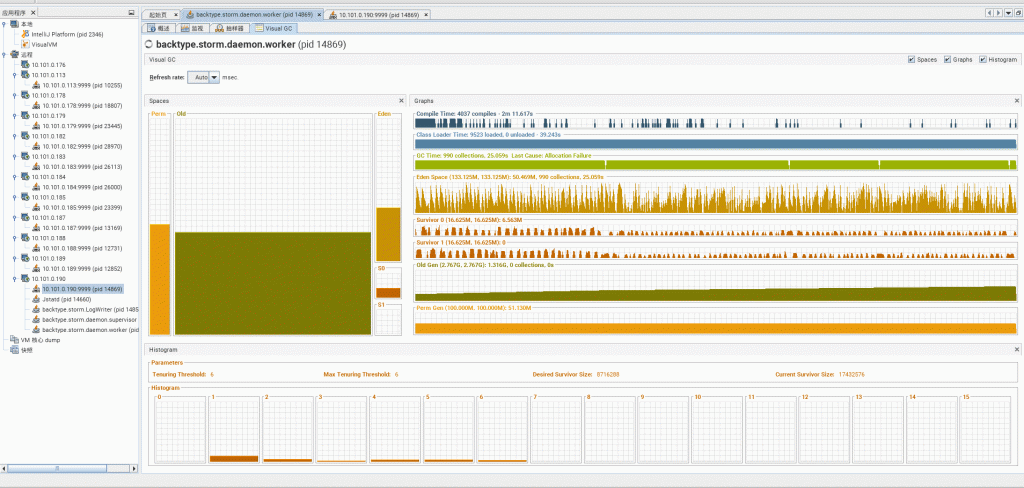
因业务不断增长,为了保证数据正常存储,对现有系统做改造与压力测试、调优
目标:承载同时在线5万个设备上传GPS(平均10秒一次)
目前GPS上传频率为10~60秒,保有量按10万计算,同时在线运行按1/2算,则,TPS5000即可保证10万设备正常运行。

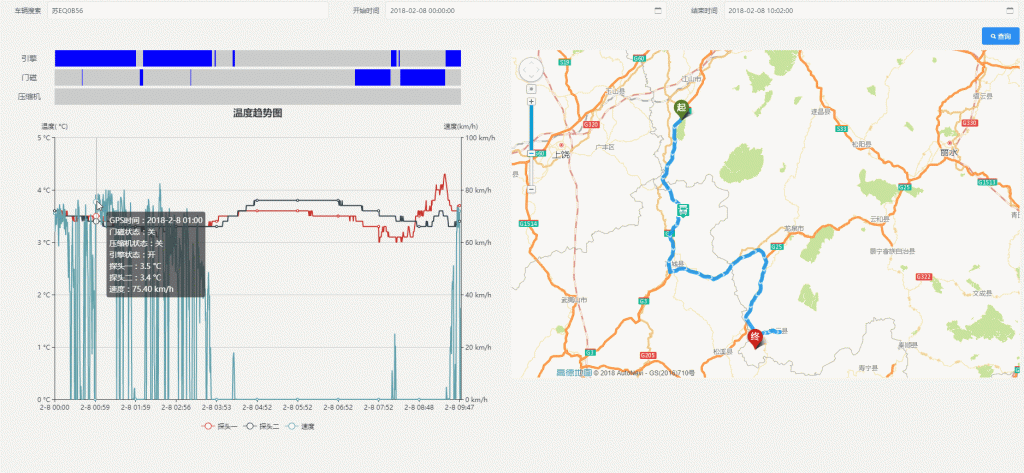
冷链(下图GIF动画,点击图片查看)
目录
项目架构与Storm处理逻辑
TCP server(Netty)调优
Hbase调优
JVM调优
最终目标达成结果
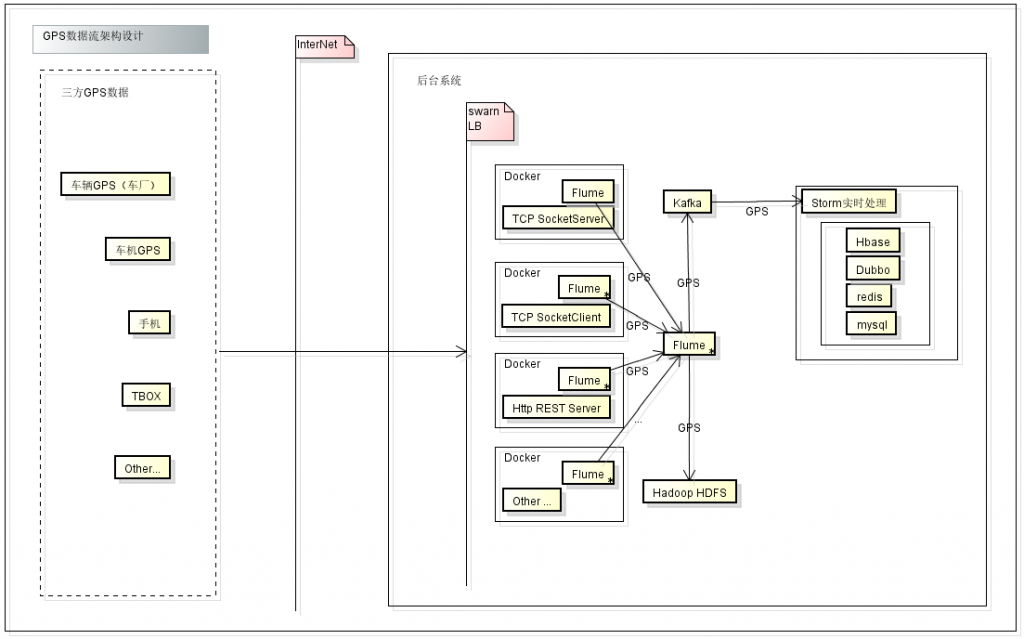
项目架构
三方设备通过tcp http 等方式发送GPS数据到Server,server通过docker做负载均衡,各个收集节点通过Flume方式收集数据发送到kafka和HDFS系统
storm通过消费kafka数据进行计算,将结果分别存储到不同的介质:Hbase,mysql,redis。
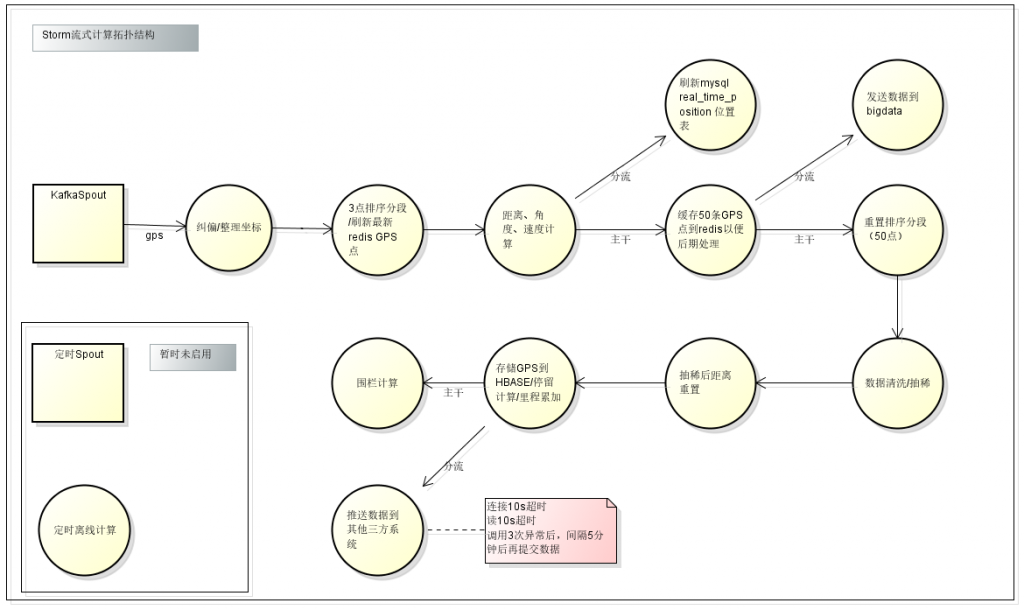
Storm数据流转
调优注意事项:
横向扩展storm集群的同时,设置worker数量,及并发度,与task数量。保证机器任务分布均匀。
避免多次数据库操作,避免多次循环
设置队列长度
设置worker jvm参数worker.childopts: "-Xms3000m -Xmx3000m -Xss256k -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:-UseGCOverheadLimit -XX:PermSize=100m -XX:MaxPermSize=100m -XX:+HeapDumpOnOutOfMemoryError -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=2"
最初的拓扑结构
实际拓扑结构
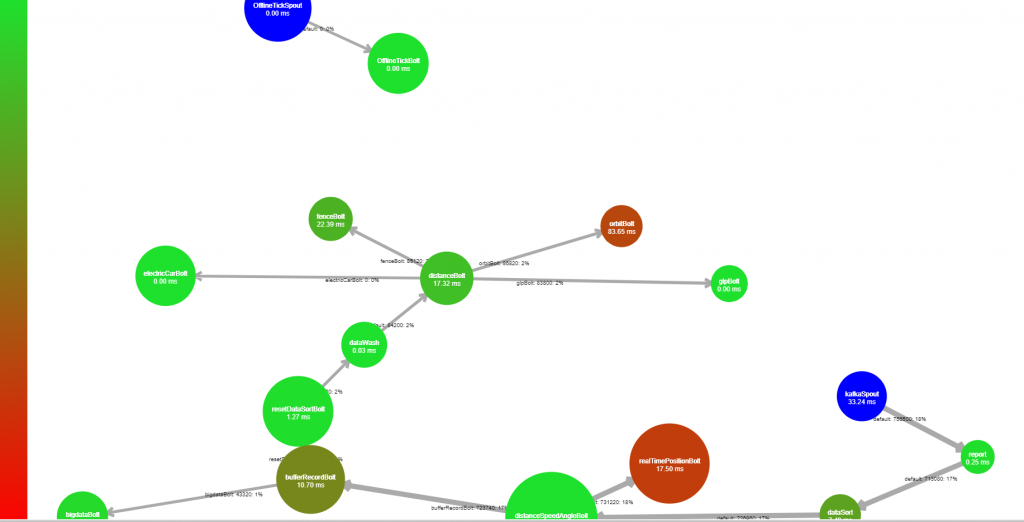
TCPserver 调优
使用Netty 做服务端
设置系统文件数句柄到10W以上。
去除应答,与sync().
Hbase调优
调整hbase region servfer handler数量到最大,因为是少量多次提交。需要提高存储的吞吐量
增加region server到5个节点
hbase client 添加缓存到2M-默认
绑定表的连接到线程
key散列-避免热点问题,也可以手动split,时间倒置,最新排最前!
增加JVM内存![]()
平均控制在10ms内存储进入hbase
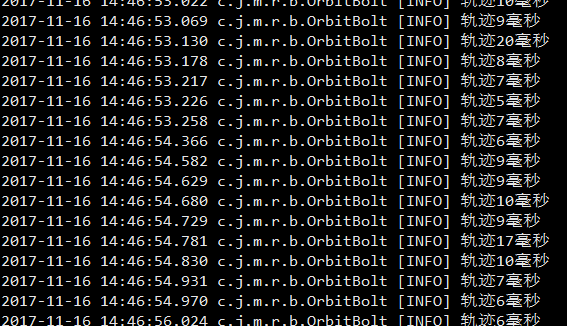
JVM调优
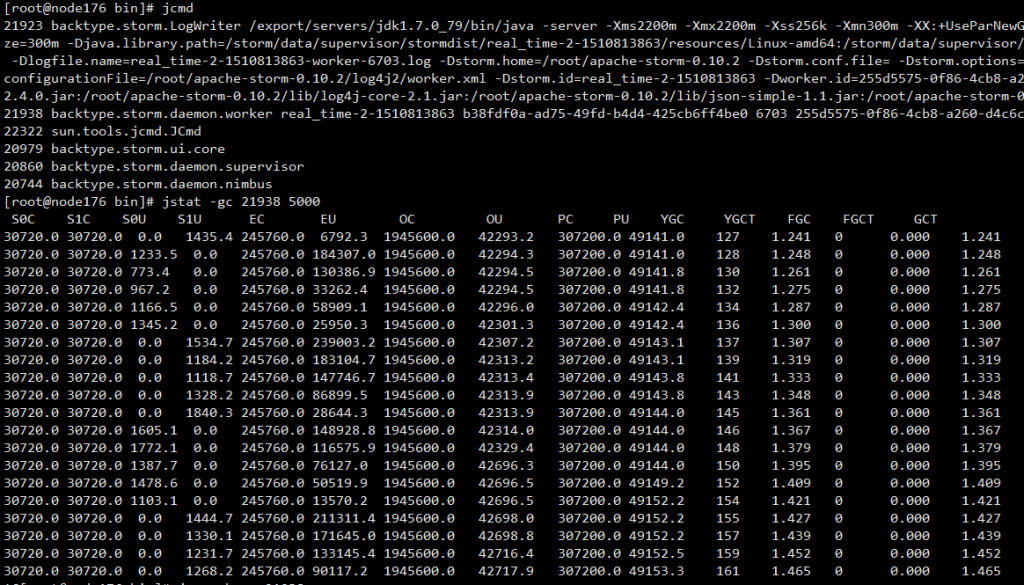
通过jstat 不断观察jvm情况调整各个端的jvm参数
flume 默认jvm为20M 根据实际情况调整
调整storm worker jvm参数
调整netty jvm参数使用并发收集器
目标达成
3000万 GPS,17GB,3小时疲劳测试。0失败 TPS4000(TPS6000可撑1小时)
netty server 24小时疲劳测试。单个连接并发1000
5+1个flume节点
5个hbase 存储节点及region server。
1 zookeeper节点
1 kafka节点
1 redis节点
17台 4核4GB storm节点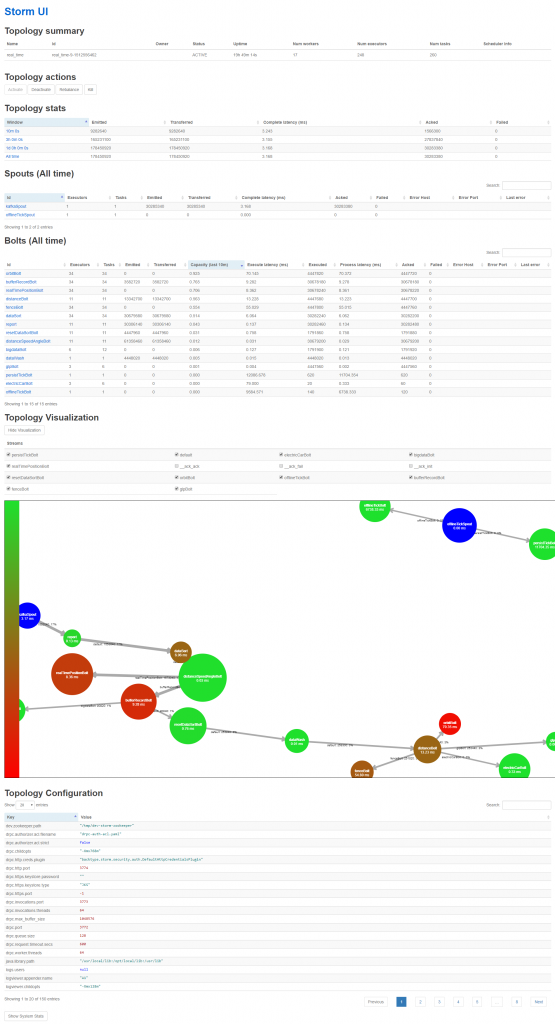
基于Storm Hbase 流式计算与存储的TPS6000调优
https://bmap.xyz/archives/1705025728456